Dataikuを用いてコードなしでAI実装
Dataikuとは、データ準備・AIモデル学習・予測・デプロイなどデータ分析のための過程をひとつのプラットフォームでできる包括的なソフトウェアです。GUI上でフローチャートを使いながら実装できるので、分かりやすく、プログラミング経験のない人でも利用できます。また、EDA(Exploratory Data Analysis)の際にいちいちコードを書かなくても可視化できるので、効率的にデータ分析できます。
Dataikuハンズオン
それではDataikuを使って実際にデータ分析をしてみましょう。まずは上記のサイトから無料版をインストールします。インストール後アプリを立ち上げると、ブラウザが開くので、マイページから”NEW PROJECT”を選択して新しいプロジェクトを作成します。ここではプロジェクト名を"ML_tutorial"としました。
データセット登録
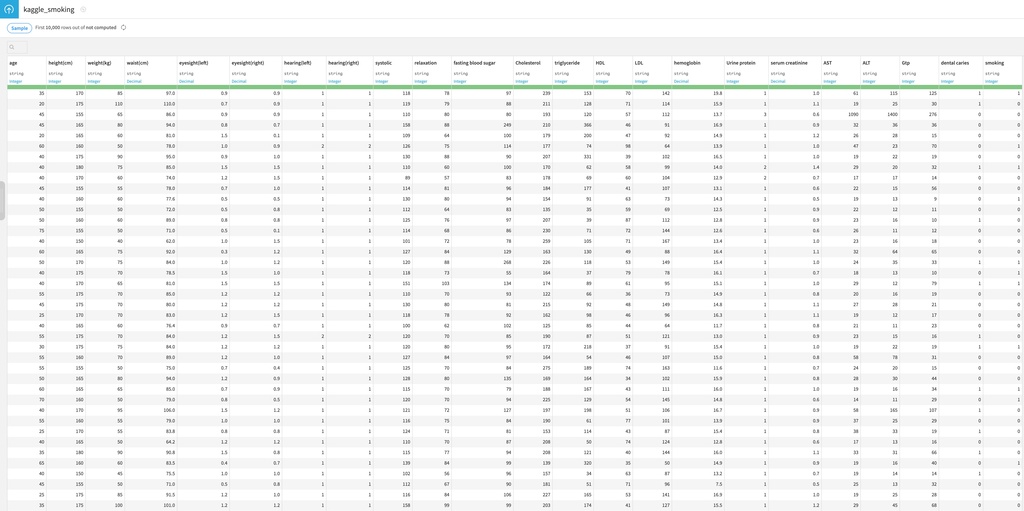
次に、“IMPORT YOUR FIRST DATASET” -> “Files/Upload your files"から学習データをインポートします。今回は例としてKaggleのSmoker Status Prediction using Bio-Signalsを使用しました。これは身長、体重、血圧など様々な生体データから喫煙者かどうかを推測する問題です。読み込むと、下図のように各カラム情報が表示されました。
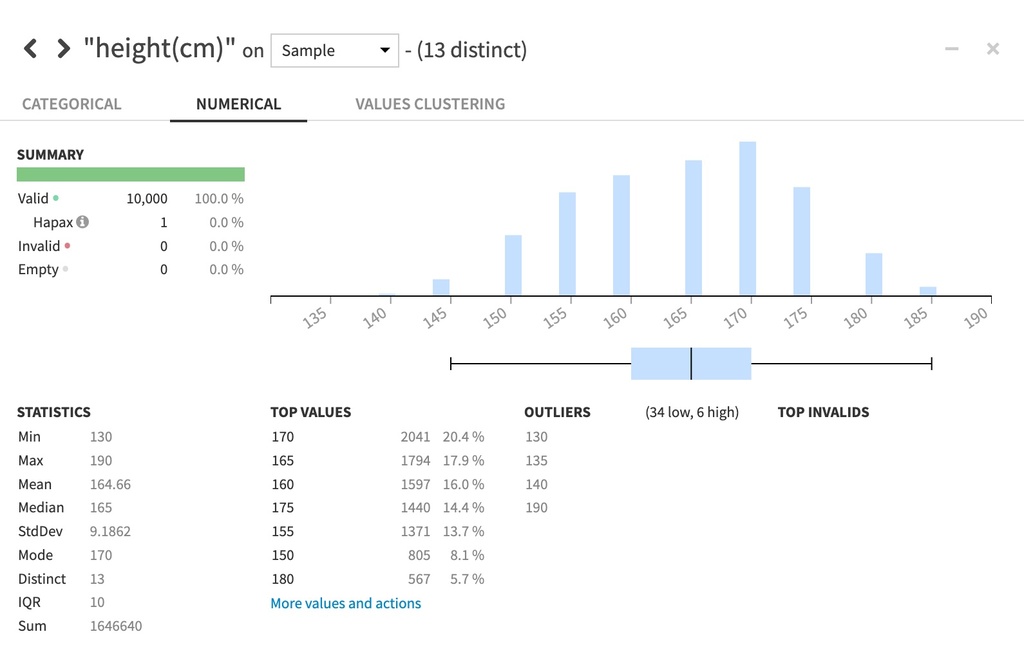
任意のカラム名を選択し、“Analyze"をクリックすると、下図のように統計情報が表示されます。例えばこのデータでは被験者の身長は平均165, 標準偏差9であることが分かります。
AIモデルを学習するために、データセットを分割しましょう。データセットアイコンを選択し、“Visual recipes” -> “Split"を選択します。Outputsに"train"と"test"という名前をADDし、“CREATE RECIPE"をクリックしてください。分割方法はシンプルに"Randomly dispatch data on the output datasets"とし、trainの割合を80%とします。
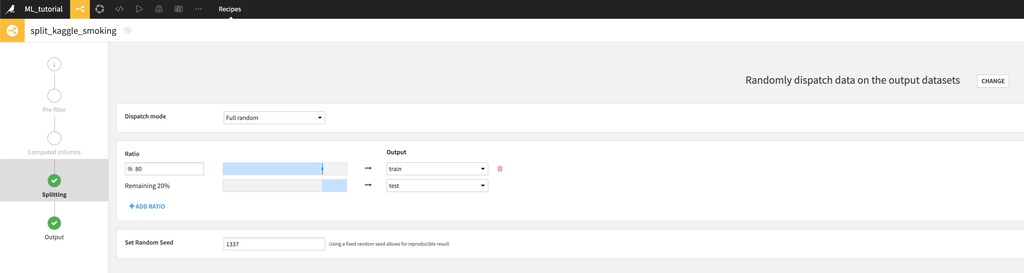
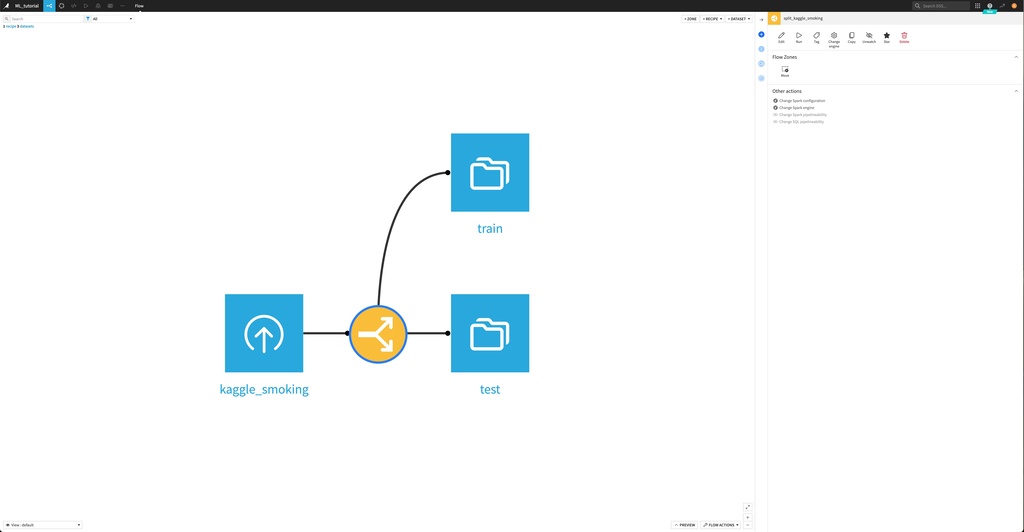
最後に"RUN"で実行して、学習データとテストデータに分割することができました。
AIモデル学習
それではいよいよAIモデルを学習していきます。trainアイコンを選択し、“Lab” -> “AutoML Prediction"を選択します。ターゲット変数に"smoking”(1:喫煙, 0:禁煙)を設定し、モデルはデフォルトの"Quick Prototypes"とします。
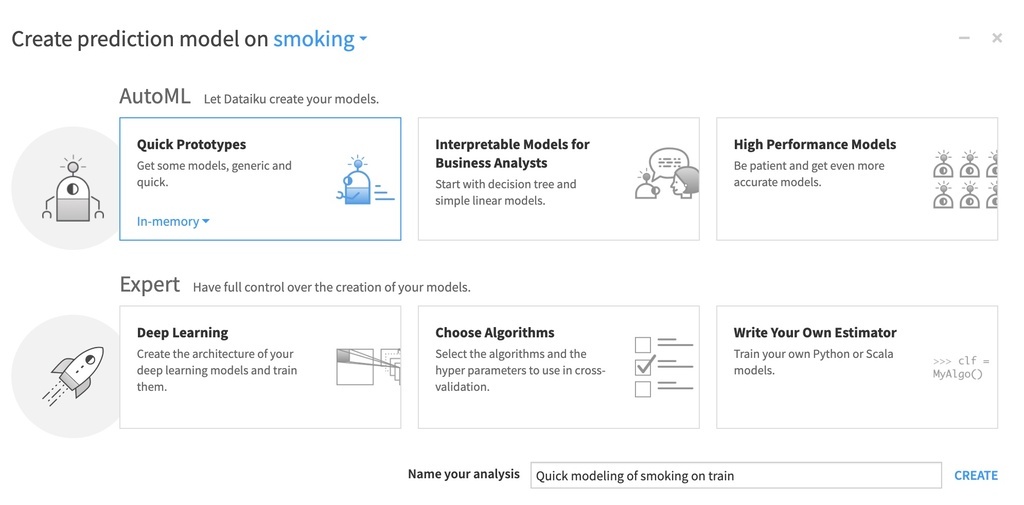
“Create” -> “Train"とすると、自動的に学習が始まります。すぐに学習が終了し、結果が出力されました。
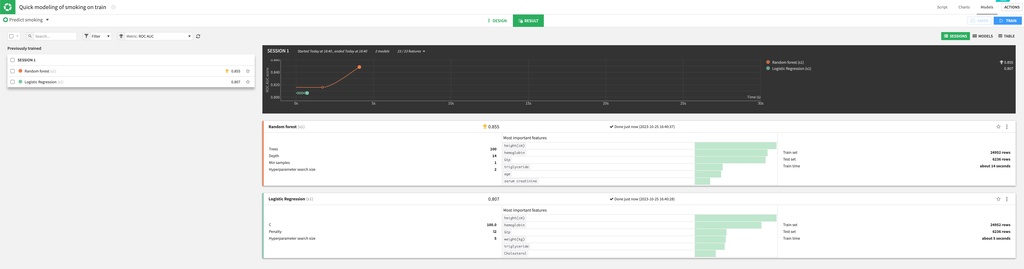
デフォルトでは、ランダムフォレストとロジスティック回帰が使用されます。学習時間・精度・ハイパパラメタ情報が可視化されます。この実験ではランダムフォレストの方が精度が高く、85.5%でした。
モデル評価
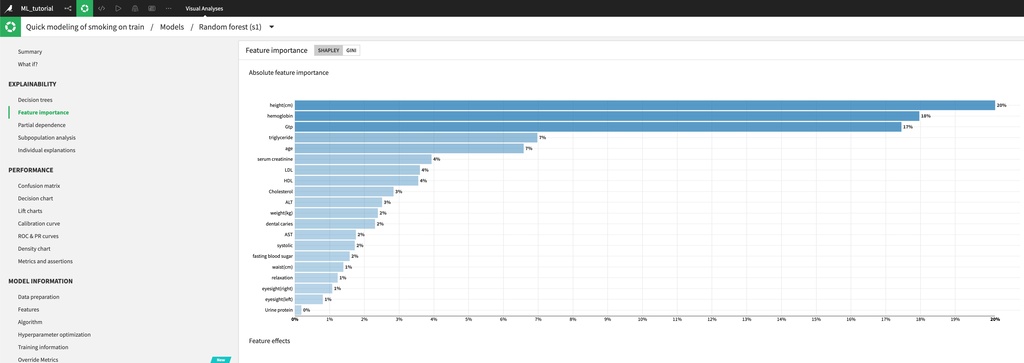
各モデルを選択すると、より詳しい情報を見ることができます。例えば、Random Forestを選択し、“Feature importance"をクリックすると、各特徴量の重要度が表示されます。この例では、身長・ヘモグロビン・γ-GTPの値が最も分類に寄与しています。なお、身長と喫煙率に相関があるとは考えにくいため、このデータセットはバイアスがかかっていると考えられます(成長期に喫煙をすると身長が伸びにくくなるという文献はありますが、本データセットは対象年齢が成人であり、未成年の時に喫煙していたかどうかの情報は与えられていません)。
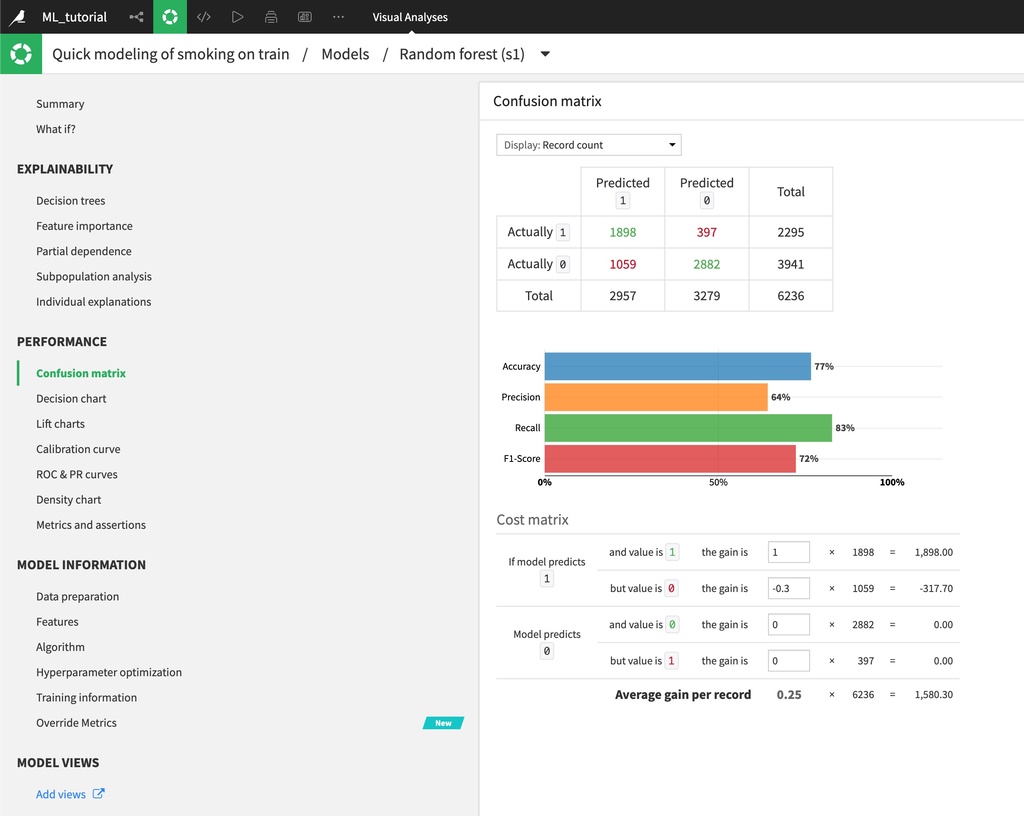
また、“Confusion matrix"をクリックすると、適合率・再現率・F1スコアなどのメトリクスが表示されます。図から、このモデルはやや過大評価していることが分かります。
テスト
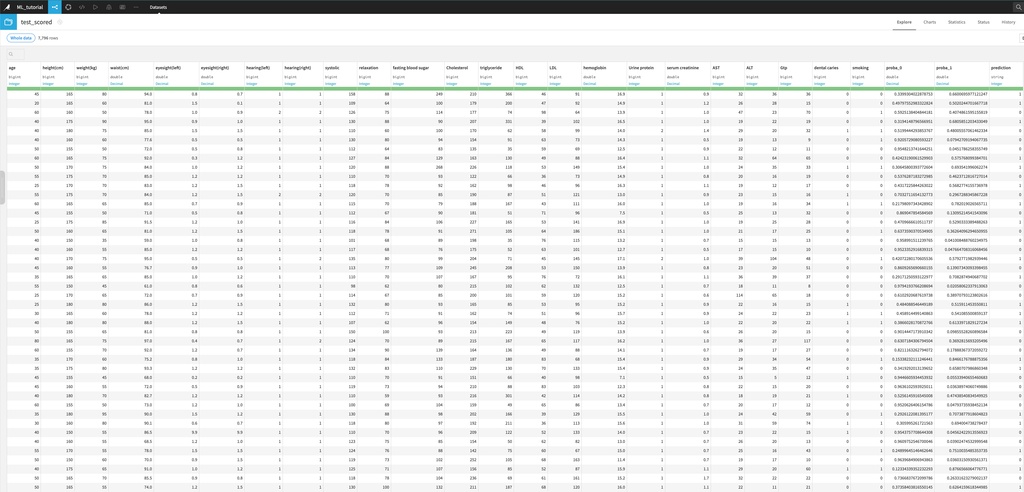
最後に、テストデータを予測してみます。右上の"Deploy"をクリックし、学習済みモデルをデプロイします。モデルアイコンを選択し、“Apply model on data to predict” -> “Score"からtestデータセットをinputに設定します。“Create” -> “Run"で実行すると、出力結果が表示されます。
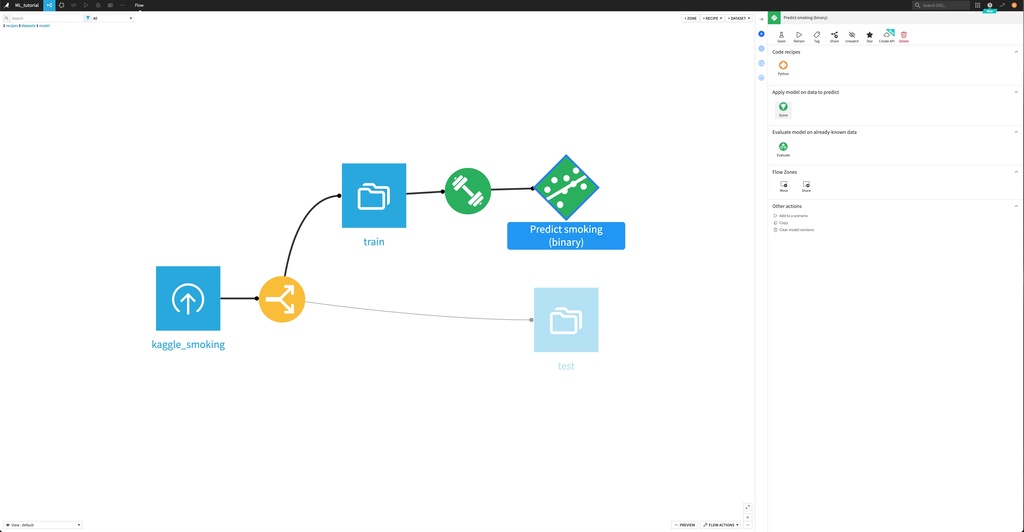
下図のように、各レコード毎に予測クラスとそれぞれの確率が得られました。
まとめ
本記事では、Dataikuを用いてAI分析の実験を行いました。個人的には、完全にノーコードでゼロからAI分析できることに驚きました。プログラミング初心者や、非エンジニアの方にも入りやすいので、よりAIやデータ分析が身近になることを願っています。また、今回紹介した機能はごく一部なので、より高度な内容をこれまでよりも効率的に実現することが可能で、現役のエンジニアにも有益なツールだと思いました。